
In the realm of modern data processing and real-time analytics, Apache Kafka has emerged as a pivotal player, revolutionizing the way data is handled, streamed, and managed. With its scalable, durable, and fault-tolerant architecture, Kafka has become a cornerstone for real-time data pipelines and streaming applications across various industries. In this article, we will explore the fundamental aspects of Apache Kafka, its architecture, key features, and delve into real-world examples to illustrate its practical applications.
What is event streaming?
Event streaming is like the brain of the digital world. It’s what makes our ‘always-on’ world tick, where everything is run by software.
In technical terms, event streaming is all about grabbing data as it happens from various sources like databases, sensors, mobile devices, the cloud, and software. This data is stored in a way that it can be accessed later. It’s also about working with this data in real-time and looking back at it, processing it, and responding to it. You can send this data to different places as needed. This way, event streaming keeps data flowing and helps us understand it better, making sure the right information is in the right place at the right time.
Understanding Apache Kafka
Apache Kafka, an open-source distributed event streaming platform, was originally developed by LinkedIn and later open-sourced under the Apache Software Foundation. It is designed to handle real-time data streams efficiently and reliably. The core concept behind Kafka is the abstraction of a distributed commit log, where data is written to a log-like structure and stored persistently.
Key Components of Kafka
- Producers: Applications that push data into Kafka topics.
- Brokers: Kafka servers that store and manage data.
- Topics: Logical channels for organizing and segregating data streams.
- Consumers: Applications that read and process data from Kafka topics.
- ZooKeeper: A coordination service used for managing and coordinating Kafka brokers.
Kafka’s Publish-Subscribe Model
Kafka operates on a publish-subscribe model. Producers publish data to specific topics, and consumers subscribe to these topics to receive and process the data. This decoupling of producers and consumers allows for high scalability, fault tolerance, and efficient data distribution.
Apache Kafka Architecture
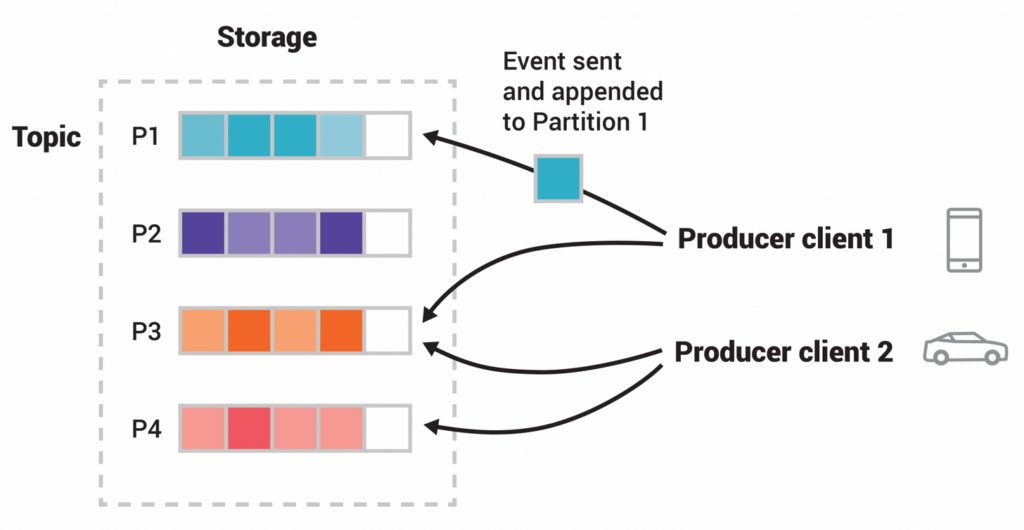
Kafka’s architecture comprises the following key elements:
Topics
Topics are the fundamental units in Kafka and act as data channels where producers publish messages and consumers consume them. Each message within a topic is assigned a unique offset, enabling efficient message retrieval.
Partitions
Each topic is divided into multiple partitions, allowing for parallel processing and scalability. Partitions store ordered, immutable sequences of records.
Brokers
Kafka brokers are servers that manage the storage, retrieval, and replication of records in partitions. Brokers work together to form a Kafka cluster, ensuring fault tolerance and high availability.
Producers
Producers push data records into Kafka topics. They determine the partition to which a record is sent based on various strategies, such as round-robin or key-based.
Consumers
Consumers read and process data from topics. Kafka allows both consumer groups and individual consumers. Consumer groups provide load distribution and fault tolerance, ensuring each record is processed by only one consumer within the group.
Key Features of Apache Kafka
Scalability
Kafka’s partitioned and distributed nature enables seamless scalability. You can easily scale up by adding more brokers or partitions to distribute the load efficiently.
Durability
Data in Kafka is persisted to disk, providing fault tolerance and durability, even in the face of failures.
Low Latency
Kafka offers low latency, making it suitable for real-time data processing and applications that require near-instantaneous data delivery.
Fault Tolerance
Kafka ensures fault tolerance by replicating data across multiple brokers. If a broker fails, another replica can seamlessly take over.
Real-World Examples of Apache Kafka
Let’s explore how Apache Kafka is utilized in various real-world scenarios.
1. Financial Institutions: Real-Time Fraud Detection
Financial institutions leverage Kafka to ingest and process a vast amount of transaction data in real time. Kafka’s low latency and fault tolerance make it ideal for real-time fraud detection systems, allowing immediate identification of potentially fraudulent transactions.
2. E-commerce: Order Processing and Inventory Management
E-commerce platforms utilize Kafka to manage order processing and inventory updates in real time. As customers place orders, Kafka ensures efficient processing and synchronization of inventory across various systems, providing a seamless shopping experience.
3. Social Media: Real-Time Analytics
Social media companies utilize Kafka to process massive amounts of data generated by users in real time. Kafka helps analyze user interactions, trends, and sentiments, allowing platforms to make informed decisions for content curation and user engagement.
4. IoT: Telemetry Data Processing
In the Internet of Things (IoT) domain, Kafka is used to handle high volumes of telemetry data generated by IoT devices. Kafka’s scalability and real-time processing capabilities enable the efficient collection, processing, and analysis of IoT data for various applications like predictive maintenance and smart city initiatives.
Conclusion
Apache Kafka has emerged as a fundamental tool for real-time data processing, enabling organizations to harness the power of data streams effectively. Its fault tolerance, scalability, and low latency make it a go-to solution for a wide array of industries, ranging from finance to e-commerce and beyond. By understanding Kafka’s architecture and key features, you can unlock its potential to drive innovative solutions and gain a competitive edge in the modern data-driven world.