
Twelve-Factor App is a twelve-point manifesto created by Adam Wiggins, one of the co-founders of Heroku, based on his own experiences, covering topics such as DevOps, technology selection, programming language, architecture, etc. This manifesto is a guide to the best practices that should be applied when developing cloud-oriented applications (Cloud Native, Cloud Ready).
The 12 factors briefly consist of the following topics.
Codebase, dependencies, config, backing services, build-release-run, processes, port binding, concurrency, disposability, dev/prod parity, logs, admin processes
Who It’s For: Software developers, software architects and DevOps engineers are the target audience of this paper. According to Adam Wiggins, anyone who develops, deploys, manages and, most importantly, decides on service-oriented applications is the addressee of this manifesto.
1. Codebase

Source code should be kept on a version control system (Git, SVN, TFS, etc.). Thanks to version control tools; development, review, versioning and deployment processes can be easily implemented.
One-to-one relationship should be established on the version control system.
One App – One Code Repo and One Code Base – Multi Platform Deployment
According to this clause, each “application” should be stored in separate code repos and each application should have a single code base. If you are using the Git versioning tool and wondering how to set up a first-principle branch strategy, you can take a look at git flows (e.g. Github flow, Microsoft Flow, etc.).
Why?
Software projects may have different code repos such as Dev, Test and Release and code is moved between repos. This approach can give you different advantages, but according to the 12 factors, it is wrong. In this approach, the outputs (so, jar, dll, etc.) are different for each environment. What is desired is that there is a single code repository and all product environments get the output from the same repository. With this approach, run-time differences between environments can be minimized.
Putting multiple applications in a single code repo goes against the first principle of the 12 factors. Applications should be separated and kept in separate code repos, so that it is easier to version applications, migrate between versions, measure code quality, break dependencies between applications and, perhaps most importantly, implement CI/CD processes more easily.
2. Dependencies
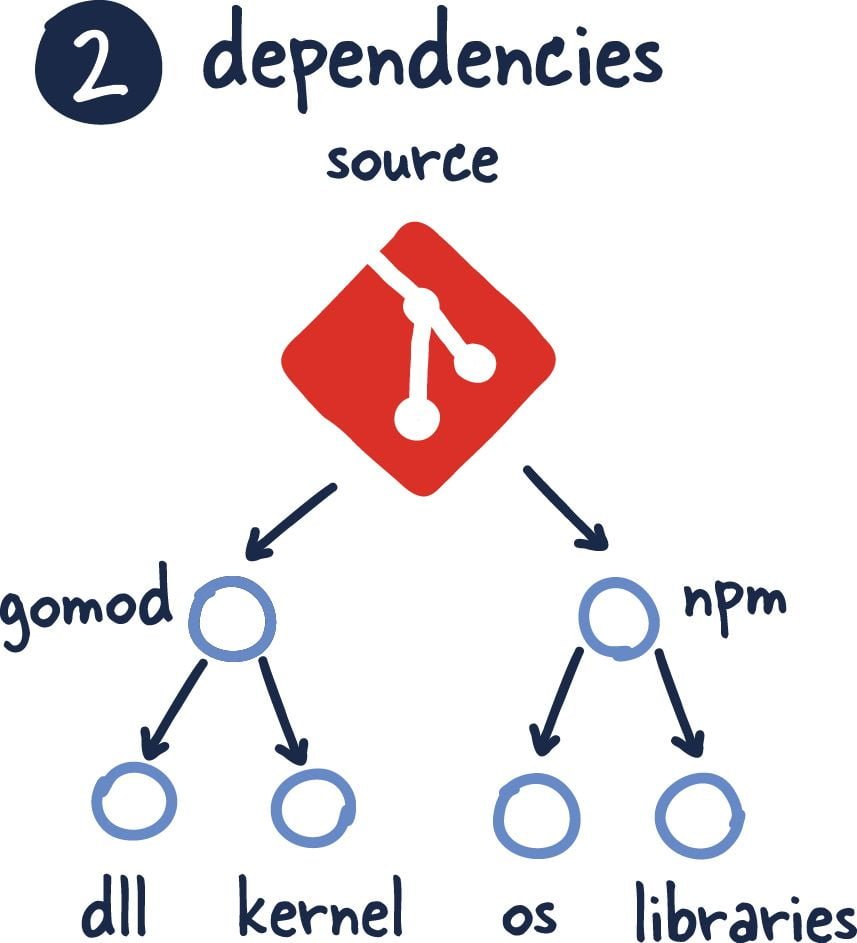
According to this principle, everything in the project (code, packages, directive files, scripts, etc.) should be packaged. Anything like helper, common, shared kernel, etc. developed for common use should be packaged using the package manager of the programming language you are developing in. Instead of moving code, dll, so, jar, etc. between projects, things to be used should be versioned and packaged. Examples of package managers are pip for Python, nuget for .net, maven for java, npm for java script. When referencing dependencies, the version must be specified; an efcore library in csproj, a spring package in pom.xml should not be defined without specifying the version number. The only case where this policy can be relaxed is if the referenced packages are developed by you and a final version is always required.
Dependencies should not be considered as code or project dependencies. For example, an IIS requirement to be added during development for a .net application or Tomcat for a Java application is a dependency. Environment dependencies can also be considered under this heading, for example, even an application that needs to be installed in the development environment is considered within this scope. These dependencies must be isolated from the application and must be manageable. All dependencies must be clearly specified.
Why?
There are many reasons for this criterion. First of all, not specifying all references from a single point (package file, pom file, etc.) will complicate both the development and the deployment process. In case of deployment to different environments, the necessary dependencies will have to be moved manually. If the dependencies are not versioned, it will make it difficult for a development package to be rolled back.
In a situation where project dependencies are not clearly specified and isolated, a developer who is new to the project will have to find these dependencies with time-consuming things such as compilation errors and log tracking.
3. Config
Everything that changes in the application between environments (dev, test, release, etc.) is a configuration. All configurations that the application needs (username, file directory, ip address, database name, etc.) should not be defined as a constant in the application. Configurations and code should be strictly separated and should not be together. Configurations should be provided as a service outside the application. Configurations and credentials should be kept separate from each other. Spring config server, vault, etcd, consul, etc. technologies can be used as well as environment variables to manage configurations.
Why?
In the scenario of using configurations without separating them from the application, the application will need to be updated and redeployed in case the configurations need to be changed. If configurations are provided as a service and applications consume this service, the configurations of all applications can be observed, managed and easily changed at runtime from a central point.
4. Backing Services
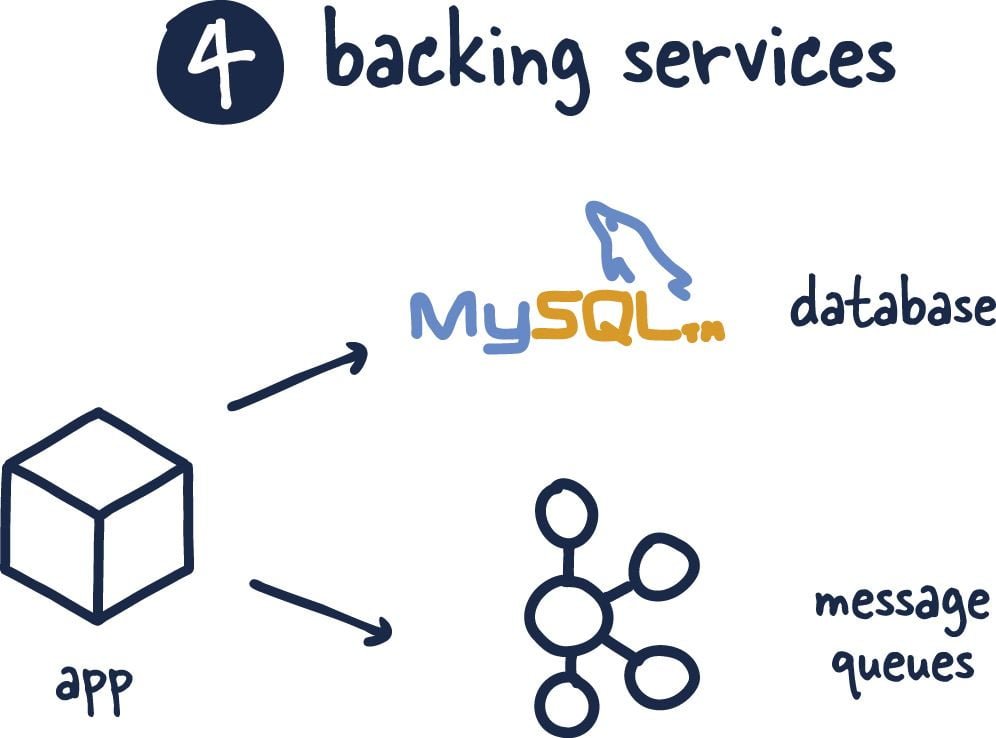
Everything such as database, API services, Cloud (S3, DB instance, etc.), social networks, mail servers, even file system are support services for the application according to the fourth principle of the 12 factors and according to this principle all services should be able to be attached and detached at runtime without closing or restarting the application. All parameters of the support services used should be manageable through the configuration service.
Why?
When you want to develop a scalable application, all the services that the application uses must allow this scaling. In accordance with this principle, if you design the support services to be pluggable and unpluggable at any time, it will be very easy to scale your application to another environment or replace the support service with another service.
5. Build-Release-Run
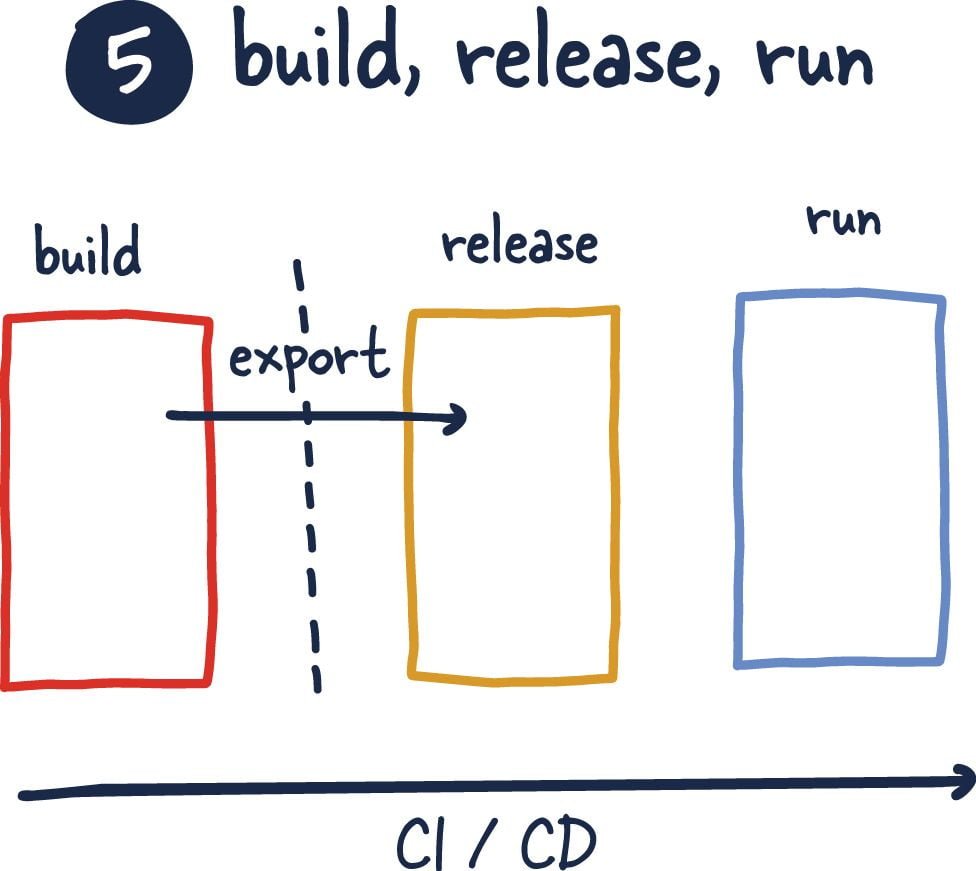
According to the fifth principle of the 12 factors, the three processes in the project lifecycle (build, release, run) should be strictly separated from each other. This principle forces the proper implementation of CI/CD processes, where you will need to establish a DevOps process and choose a suitable build deployment tool (Azure DevOps, AWS Pipeline, Travis, Jenkins, Gitlab CI/CD, etc.). According to this principle;
Build Process:
- It can have as complex processes as desired.
- The process should be deterministic.
- The build machine should be separate from the developer’s work environment.
- Configurations should not be made at this stage, the source code should be compilable on the build machine as in the developer.
Release Process:
- The versioning of the source code should be in this phase.
- Configurations can be made at this stage.
Run Process:
- The process should be very simple, the project should run very easily.
- The released code should be executable without any configuration requirements.
- At this stage, bug fix operations should not be performed on the project. If there is a bug fix requirement, the process should be started again.
Why?
In an environment where the developer fixes all bug fixes during runtime, it will not be possible to version the application, switch between versions, and archive the application and application packages. In the case where these three processes are separated from each other, knowing that the release code is ready to run at any time will enable deployment at any time.
Explore the most popular software build tools: https://devopstipstricks.com/the-most-popular-software-build-tools-in-devops/
6. Processes
The sixth principle says: design your processes to be stateless. Instead of storing the state it needs in-memory, a stateless application stores it in a persistent place (e.g. a database). Whenever states are needed, the data should be fetched from support services.
Why?
Even if your technological structure (e.g. Kubernetes) allows scaling, the applications you develop should be able to scale. Stateless processes allow applications in microservice architectures to scale horizontally. When an application where all states are kept in-memory is distributed over multiple pods, it is not possible to maintain the integrity of the states. For this reason, it would be more logical to keep the relevant states on an external support service.
7. Port Binding
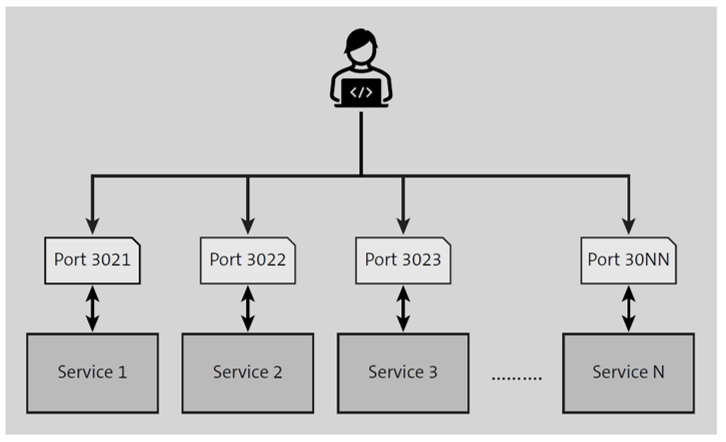
Services should be exported through ports, file path should not be used when exporting. Instead of opening each .net application deployed on IIS or each java application deployed on Glassfish as http://hostname/myapp1, http://hostname/myapp2, http://hostname/myapp3, each application should be opened over different ports such as http://hostname:5000, http://hostname:5001.
Why?
Opening each service to the outside via port will make it easier for the DevOps team in the deployment processes of these services. When you want to dockerize your applications, path binding may not always be easy. When you want to switch to a microservice architecture, there will be a need for communication between services, and the service discovery tools you will use in this case will search for the ports you open to the outside. When you open them through a single application server, it will not be possible to fragment these applications.
In this way, you can also benefit from the benefits of API Geteway tools (limiting, service mapping, etc.).
8. Concurrency

Under the Process principle, we talked about what a process is. According to the eighth principle, the tasks within an application (user interfaces, backend services, etc.) should be separated and treated as different processes. For example, a user interface with charts, etc. developed with javascript and the user authentication backend service in this application should be separated from each other.
Why?
Who doesn’t want their applications to be scalable. Suppose we don’t follow the eighth principle and the UI and a backend service that serves this UI and performs tasks that consume a lot of system resources are in the same jar or dll. Suppose you want to scale this system because of the increase in the number of users, what you would do is increase the server resources, which is called vertical scaling, or copy the same application and scale it vertically on another machine. How far can you scale in this case? In vertical scaling, you will reach the physical resource limits. When you scale horizontally, in each jar or dll you copy, you have both a backend service that will cause scaling that increases resource consumption and a UI project that consumes very few resources and does not need scaling. If you separated these two processes from each other, you could only scale resource-intensive tasks.
9. Disposability

The ninth principle says that the application should be ready to run and shut down at any time. The application may receive many user requests instantaneously, in which case the application should scale and new instances should be created. The scaled application should stand up very quickly and start processing some of the requests.
When user demand decreases, the instance should be able to gracefully shutdown, that is, it should be able to shut down by running the shutdown scenario without losing the current requests. User requests sent to an instance that is about to shut down, according to the shutdown scenario you have designed; The instance should be able to be closed by processing the existing requests without receiving new requests or by throwing the instance back into the processing queue, including all the requests that are about to be processed.
Why?
Let’s give a real life example to understand why. As you know, ÖSYM results page is exposed to intense user requests only during exam times. When the exam result is announced, the backend service that will retrieve the result from the database and return it to the user should be distributed to new instances as soon as the traffic increases, and the application should start responding to new requests very quickly. After scaling, the application should be up and running in 10 minutes, which is not an acceptable time for an instance that will only run for an hour.
When user traffic decreases, there will be requests waiting to be processed on all existing instances. With the decrease in traffic, you can close these instances as unnecessary, but if a user who has logged in and is waiting for the result is on this instance, this user will receive a direct error and will be asked to log in again. In order to prevent this situation, gracefully shutdown scenario should be added and exam result requests should be directed to the open instance, so that the user will see the result without even realizing anything.
10. Dev/Prod Parity
The tenth principle says that differences in the development and working environment of the project should be eliminated, the dev and prod environment should be “the same”. According to the twelve factors, there are three difference factors that will prevent continuous deployment. These are differences in time, personnel and tools. The fewer these differences, the easier continuous distribution and bug fix will be.
Time: The time between the development process and the go-live of the project is called the time gap, and this time should be reduced to a daily or even hourly level instead of weeks or months.
Personnel: In the traditional approach, the people who develop, deploy and monitor the project are different from each other and are usually only involved in the relevant process. Twelve factors say that the people who develop, deploy and monitor the application should be the same.
The feature team should have the skills to develop, deploy and run the application.
Tools: The tools used by the developer in the development environment and the tools used in the production environment of the application should be the same as much as possible. While the developer is developing and testing on Linux, it is not recommended to work on Windows Server in the production environment. Likewise, the difference between the Java or .Net version in the development environment and the version in the environment where the deployment will be made is considered as a tool difference and these differences should be minimized as much as possible.
Why?
If the time gap is large, that is, if the code written by the developer is taken to the prod environment months later, it may be difficult to fix the bugs that will occur in this process because too much time has passed and the improvements made may have been forgotten.
If the personnel doing the work are different, if those who write, deploy and monitor the code are different, they will probably blame each other in case of a bug. In this scenario, no one will own the project, and the developer will be able to take the ball out of my court after the development process, but if these processes are done within a single team, the product will be owned by that team and the team will completely dominate the product.
In case of differences between environments, it can never be guaranteed that a product that works in dev and test will work in prod environment.
11. Log
According to the twelve factors, logs are a flow and should be treated as a flow and never as a file. The application should not be interested in storing or processing logs. The application should write logs as system out and leave them. The collection and processing of logs should be done by another tool. Logs should have integrity within themselves and this integrity should be ensured in scaled and parallel applications. Logs should be timestamped and stored according to this timestamp.
Why?
Giving applications tasks like log storage, processing, etc. means extra load on the application. When an application that runs on multiple instances at scale has to store logs in files, it will need to synchronize them when the instances are closed because those files will be deleted with the instance. Writing to a backend service instead of the file system means overloading the application every time a log is generated.
12. Admin Process
Factor twelve says that in the first phase of the application deployment cycle, you may need to perform some one-off operations (e.g. bash operations such as running a database migration script, defining system variables, etc.), in such cases, maintain standards, use the same code base for these operations and automate the process as much as possible. According to the twelve factors, programming languages that support REPL (Python, Ruby, *Java, Go, Rust, etc.) should be used as much as possible and these one-off tasks should be done through the shell provided by the programming language.
Why?
Automating one-off jobs allows the application to be migrated, handed over or easily maintained by someone else. Since one-off jobs are one-off, they are usually done once, forgotten, and the people who do them may not stay the same forever. If you use languages that support REPL, you can connect to all instances with a single tool and perform one-time operations directly on the shell in a very easy and secure way.
Sources
https://12factor.net
https://roots.io/twelve-factor-wordpress/
Beyond the Twelve-Factor App